メニュー
目次
情報の圧縮
コンピュータにおける情報量の表現
コンピュータで扱われる情報量を表現するために,次の単位が使用される.
- bit(ビット) 情報量の単位.二進数の一桁分で,0か1か二者択一の情報だけを表現する.
- byte(バイト) 8bitの情報.二進数で00000000から11111111までの256(=28)通りの数を表現できる.
- Kbyte(キロバイト) 接頭辞Kは,1024(=210)を意味する.通常の1000を表すkと区別すること.
- Mbyte(メガバイト) 接頭辞Mは,1024K(=1024×1024).
- Gbyte(ギガバイト) 接頭辞Gは,1024M(=1024×1024×1024).
- Tbyte(テラバイト) 接頭辞Tは,1024G(=1024×1024×1024×1024).
※註1 byteは,本来はアルファベット1文字を表現するのにコンピュータでもっとも自然に扱うことができる単位として呼称された.このため昔は6bitや9bitを1バイトとするコンピュータも存在したが,現在では1byte=8bit以外として動作するコンピュータ以外のものは絶滅した.
※註2 ここで挙げた接頭辞は,二進接頭辞と呼ばれる.通常の103や106などを意味する接頭辞は,SI接頭辞として規定されている.SI接頭辞では1000を意味する記号がkのため,二進接頭辞のKと区別できるが,M,G,Tに関しては通常のSI接頭辞も大文字で表記されるため区別がなく,文脈でどちらの意味か判断するしかない.コンピュータ関係の内容なら二進接頭辞であることが多いものの,外部記憶であるハードディスクの容量に対しては伝統的にSI接頭辞が用いられることがあり,注意が必要である.
byteという単位は,おおよそアルファベット一文字分の情報量を表すものと理解すればよい(日本語の場合には,一文字表現するのに2byte必要).ただしワープロの文書ファイルの場合には,文字の大きさや色など書式情報を大量に含むため,文書ファイルのサイズは文字数換算よりも数十倍大きくなる.
情報圧縮の考え方
ある情報の表現方法を工夫することで,必要部分の情報の内容を(情報量)を減らすことなく,見掛けの表現量を減らすことを情報の圧縮と呼ぶ.情報を圧縮するには大きく次の2つを考える.
- 情報の表現から冗長性(redundancy)を取り除く
- 情報の中から不必要な情報/影響の小さい情報を取り除いて情報量自体を削減する
1.の例として,下記のような二進数のデータを考える.4ビットの先頭を見ると必ず0になっているため,これを省略することが可能である.その代わり,「頭に0を付ける」という約束を知っていないと元の情報を復元できない.省略可能な部分のことを冗長な部分と呼ぶ.冗長な部分としては,ある条件が決まればもう一方も必ず決定される情報や,一定数繰り返される情報などがある.
0101 0111 0000 0010 → 101 111 000 010
2.の例として,次のような画像を考える.この画像には,文字「A」の他にも「筆跡」や「色」や傍に見える「ペン」などの情報が存在する.しかし,仮に色に関する情報が不要だとすれば,モノクロ画像に変換することで必要な情報量を減らすことができる.さらに,文字だけが必要な情報であればASCIIコードとしてわずか1byteで表現できる.その代わり,他の情報は捨てられてしまい,後からその情報を復元することは絶対に不可能となる.
 (22.8Kbyte)→
(22.8Kbyte)→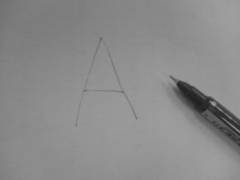 (14.5Kbyte)→ASCIIコード65「A」(1byte)
(14.5Kbyte)→ASCIIコード65「A」(1byte)2.の方法で圧縮を考える場合,「何が必要な情報なのか」がはっきり定義されていなければならない.
実際に情報を圧縮するにはエンコーダ(encorder)と呼ばれる圧縮プログラム(compressor)を使用する.当然,圧縮されたデータは元に戻さなければ使用できない.元に戻すプログラムはデコーダ(decorder)と呼ばれる伸張プログラム(decompressor)を利用する.「圧縮」に対する言葉は「伸張」であるが,この代わりに「展開」が使われることも多い.また俗語として広く使われる言葉には「解凍」もある.decodeを訳した「復号化」も用いられることがある.
※捕捉「展開」という言葉は実は「アーカイブ(archive)の作成」または「書庫の作成」と対応する言葉である.アーカイブ(書庫)ファイルとは,ある関連した複数のファイルを結合してひとまとめに再作成したファイルのことである.アーカイブファイルから必要なファイルだけを取り出したり,全部のファイルを取り出すことを「展開」と呼ぶ.複数の関連したファイルをまとめてダウンロードできるようにしておいたり,データのバックアップをひとまとめにしておくような用途で使用される.「書庫」は,本来は「圧縮」とは無関係の独立した概念であるが,アーカイブファイルは複数のファイルを結合するためにファイルサイズが巨大になるため,アーカイブファイルは圧縮して保存されることが多い.このため,アーカイブ作成プログラムは,書庫作成だけでなく圧縮機能を持つことが多い.ただし,UNIX系OSでは伝統的に両者が別のプログラムとして提供されることもある.
また,当然のことながら圧縮と伸張(アーカイブの作成と展開)には,両者が対応するプログラムであることが必要である.先の例のように,先頭の0を取り除いたりするなどのように,どのようにエンコードしたのかという約束事がわからないとデコードできないためである.
可逆圧縮と非可逆圧縮
1.の方法は,完全に元の情報に戻すことができるため,可逆圧縮(Lossless compression)と呼ばれる.それに対して2.の方法を使用すると,元の情報に復元できないため非可逆圧縮(Lossy compression)と呼ばれる.
元のデータサイズに対して圧縮後のサイズの比率を,圧縮率と呼ぶ.可逆圧縮では,冗長部分だけを削除するためそれほど圧縮率があがらない.実際の圧縮率はもちろん圧縮したいデータ自体に依存するが,通常は元のサイズの半分程度に圧縮できれば良い方である.対して非可逆圧縮では情報量自体をばっさり削除するため,使用するデータ次第で1/10以下など劇的な圧縮率となることが多い.
テキスト情報は,文章の一文字でも変更されると意味が変わってしまうことがあるため,可逆圧縮することが一般的である.
※文章を自動要約できれば非可逆圧縮できるようになるかもしれないが,時と場合/目的に応じて要約の仕方が異なる以上,万人に役に立つような(一般的にどんな文章の圧縮にも利用できるような)自動要約プログラムを作成することは極めて難しい.
音声・画像・特に映像データに対しては,元々の情報量が多いこともあり非可逆圧縮が使用されることが多い.これらは,人間の聴覚・視覚特性を利用して,うまく目立たないような情報を捨てることで圧縮される.例えば人間の眼は明度には敏感であるが,色には鈍感なため,色情報を都合よく置き換えることで圧縮する.
可逆圧縮
可逆圧縮には,画像・音声などいろいろなデータ種類に関係なく適用できる一般的なものがある.しかし,主としてテキストに対する圧縮方法として利用されてきた.可逆圧縮で代表的なものは次のようなものがある.
- ハフマン圧縮法
- LZW圧縮法
- ランレングス
ハフマン圧縮法は,圧縮したい文章の中で,文字の出現確率によって決定されるハフマンコード(二進数で表記)を算出し,各文字に対応する変換表を作成する.このとき出現確率の高い文字ほど,短い桁数の二進数で表現可能となるように割り当てる.例えば次のようになる.
出現確率 1位 「e」→ 000 出現確率 2位 「t」→ 111 出現確率 3位 「a」→ 0100 出現確率 4位 「d」→ 0101 出現確率 5位 「o」→ 0110 出現確率 6位 「 」→ 1000 (略) 出現確率10位 「f」→ 00100 (以下略)
この変換表に従い,文章中の一文字一文字を対応するハフマンコードに置き換えることで,文章全体の表現を短く圧縮できる.元のデータではどの文字も1byteで表現されていたとして,もっとも頻出する文字「e」が100回使われていたとしたら,その8×100bitが,3×100bitまで圧縮できる.あまり使われない文字が8bit以上のハフマンコードに割り当てられたとしても,文章全体では短くなる計算である.
ただし,この方法で圧縮されたデータをデコードするためには,この変換表の情報が必要となるため,圧縮したデータにこの変換表自体を追加する必要がある.
LZW圧縮法は,考案にかかわった三人の頭文字から名付けられた.文字単位ではなく,単語単位で変換コードを割り当てる.例えば英語で頻出する「 the」などを短いコードに割り当てることで効率良い圧縮をはかる.変換表には単語を登録するため,「辞書」と呼ぶ.この辞書の項目数は文章により巨大となるが,登録する単語の文字数を制限することなどいろいろなバリエーションが存在する.
この方法のポイントは,この辞書を圧縮作業中にその場で動的に作成することにある.あらかじめ一つの文字は辞書に載せる作業をしておき,それから圧縮したいファイル内容を一文字ずつ読み込み,それがすでに辞書に載っていなければ新たに辞書に追加し,載っていればさらに一文字ファイルから読み込んで単語とみなし,辞書を調べる.それを繰り返しながら変換作業と,辞書登録作業を続行する.デコードする際にも動的作成できるように工夫されているため,ハフマン圧縮法のような統計的方法とは異なり,圧縮データに辞書の情報を追加する必要がない.一般にハフマン圧縮よりも圧縮率が高くなる.
ランレングス圧縮は,画像の圧縮に用いられることが多い.画像データにおける一番単純な方法である.その考え方は次のようなものである.例えば,次のような色を持った画素の並 びがあったとき,それを同じ色が何回現れたか記録するように変換する.(「連続した色」(run)の繰り返しの「長さ」(length)を記録する.)
「赤赤赤青青青青緑緑」 → 「赤3青4緑2」
変換後の方がより短い表現となっている.これを利用して画像情報を格納すればサイズを小さくできる.
※実際には圧縮率を高めるためにさらにいろいろ工夫が必要である.
非可逆圧縮
非可逆圧縮には,画像・音声データなどデータの種類に特化した非可逆圧縮方式がそれぞれ存在する.画像や音声に対する圧縮方法については,その種類に関連する各ページで説明する.
圧縮プログラムのファイル形式
これらの圧縮方法を考え方を利用して,実際にファイルを圧縮するためのプログラムが作成されている.多くのプログラムが作成されて利用されているが,プログラムが異なると例え利用する圧縮方法が同じであっても圧縮方法の細かい部分の実装(例えば辞書サイズの上限など)が異なったり,圧縮結果をファイルに格納する形式が異なる.このため,あるプログラムで圧縮したデータは,原則としてそのプログラムでないと伸張できない.
実際に利用されている圧縮プログラムは,アーカイブ(書庫)作成ソフトとして利用されるものが多く,一般的には次のような書庫形式のファイルを作成する.
- ZIP形式 WindowsXpの「圧縮フォルダ」機能で利用される形式
- LZH形式 日本で普及したlhaと呼ばれるソフトで利用される形式
- tar.gz形式 UNIX系OS(Linuxなど)で利用される形式
これら,広く一般に普及した圧縮ファイル形式に対しては,互換性のあるプログラムが作成されることも多く,書庫作成に用いたプログラムでなくても展開が可能である.フリーソフトとして,これらの複数種類の圧縮ファイル形式に対応した解凍ソフトが広く利用されている.
これら書庫作成プログラムは,テキストだけでなく,画像や音声など様々なバイナリファイルにも適用することができるものの,圧縮するという観点から考えるとファイルサイズを小さくすることはできないことが多い.すでに圧縮済みの画像ファイル(例えばJPG形式の画像)などを,このツールで圧縮しても,すでにぎりぎりまで圧縮されたデータであるためそれ以上の圧縮はできないためである.ファイルサイズはむしろわずかばかり増えることもある.もちろん,複数の画像ファイルをまとめる書庫の作成という観点ならば意味がある.